NLP学习:RNN Encoder and Decoder with Attention
RNN Encoder and Decoder
基本思路
在传统的RNN网络中,将我们的句子序列输入给网络后,RNN会将输入序列映射为固定大小的向量,长度和输入序列一致。当我们面临输入输出不等长任务,例如机器翻译。输入和输出序列显然长度不一致。这时候我们需要训练RNN,使其能够将输入序列映射到不一定等长的输出序列。
我们将网络的输入记为$\boldsymbol X = (\boldsymbol x^{(1)}, \boldsymbol x^{(2)}, …, \boldsymbol x^{(n_x)})$,称这个输入为上下文,我们希望经过网络,能够生成一个能够表示该上下文序列$C$的值。这个值可能是一个向量或者是向量组。
我们可以使用RNN的最后一个隐藏层输出作为网络的代表向量$C$,这个值可以理解为编码后的上下文序列。
之后,我们需要将该序列解码为目标输出序列。即,模型希望学习到条件概率 \(p(\boldsymbol y^{(1)}, \boldsymbol y^{(2)}, ..., \boldsymbol y^{(n_y)}|\boldsymbol x^{(1)}, \boldsymbol x^{(2)}, ..., \boldsymbol x^{(n_x)})\)
模型搭建
如图所示,基于RNN的Encoder-Decoder模型由编码部分和解码部分组成。
- 编码器(encoder)或读取器(reader)或输入(input),通过RNN(其他循环神经网络)计算出最后一个隐藏层状态$h_{nx}$,将其作为$C$。
- 解码器(decoder)或写入器(writter)或输出(output),通过另外一个RNN,将输入的$C$ 通过一定方法解码为输出序列$\boldsymbol Y=(\boldsymbol y^{1}, \boldsymbol y^{1}, …, \boldsymbol y^{n_y})$。
这种框架的创新点在于,不限制输出和输入之间的长度一定相等,从而使一个序列映射为另外一个不等长序列。
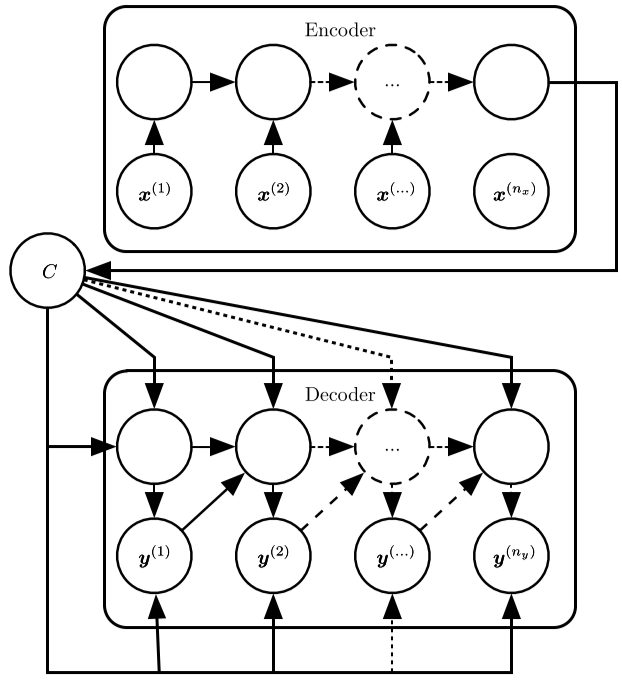
使用$h_t$代表Encoder的各个时刻的隐藏层状态,用$s_t$代表Decoder各个时刻的隐藏层状态。
\[\boldsymbol h_t = f(\boldsymbol h_{t-1}, \boldsymbol x^{(t)})\\ \boldsymbol s_t = f(\boldsymbol s_{t-1}, \boldsymbol y_{t-1}, \boldsymbol c)\]计算$\boldsymbol y^{(t)}$的方法为
\[P(\boldsymbol y^{(t)}| \boldsymbol y^{(t - 1)}, \boldsymbol y^{(t - 2)}, ..., \boldsymbol y^{(1)}, \boldsymbol c) = g(\boldsymbol h^{(t)}, \boldsymbol y^{(t - 1)}, \boldsymbol c)\]其中,$\boldsymbol c$通常为Encoder最后一个隐藏层的值,即$\boldsymbol h_{n_x}$。$f$和$g$为两个函数,$f$可以为各种形式的RNN,$g$应该为一个归一化的概率密度函数。
直观上理解,Encoder实际上是将序列编码为一个向量,而Decoder恰好为普通RNN层的逆操作,即将一个编码后的序列向量解码为一个序列。
但是这种方式的缺点在于,一个最终的向量不一定能够有效地代表我们的输入序列,因此提出了Attention机制。
Attention机制
基本思路
上文提到了,用Encoder最后时刻隐藏层的值不能有效代表整个序列。那么我们是否可以给Decoder输入所有时刻隐藏层值的加权平均来解决这个问题。
即,之前的序列表示$\boldsymbol c = \boldsymbol h^{(n_x)}$,我们改用$\boldsymbol c = \sum_{t=1}^{n_x} \alpha_t \boldsymbol h^{t}, \sum_{t=1}^{n_x} \alpha_t=1$来作为序列的表示。
Attention机制的关键之处在于如何计算权重的值,下边我们来介绍一下答题思路和权重计算方法。
模型搭建
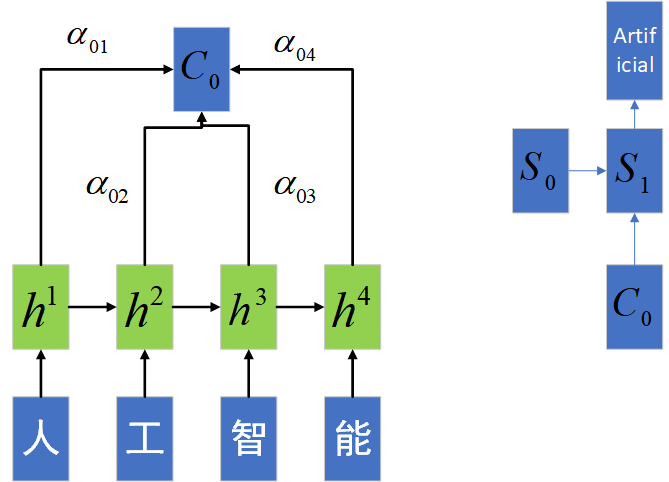
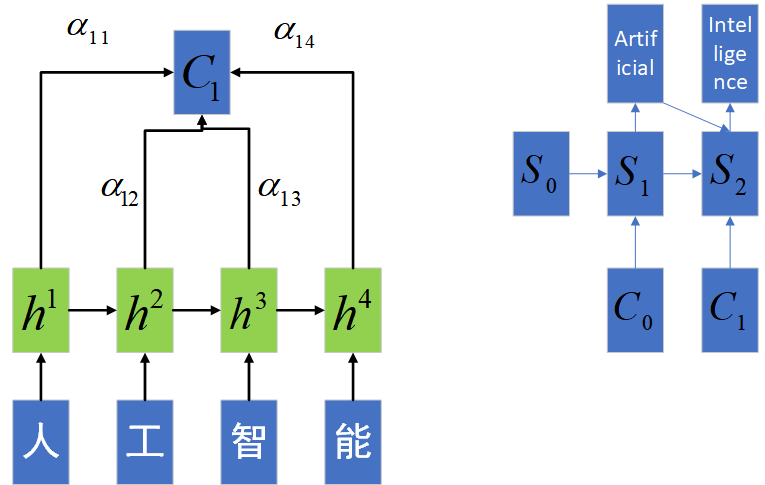
如图所示,模型的基本搭建思路和上边并无太大区别。都是通过一个Encoder层将序列编码,然后将编码后的值输入个Decoder层解码,输出最终的序列值。其中,$\alpha$的计算方法为
\[e_{ij}=a(s_{i-1},h_j)\\ \alpha_{ij}=\frac{\exp(e_{ij})}{\sum_{k=1}^{n_x}\exp(e_{ik})}\]其中$a$为一个相关性函数,来衡量$s_{i-1}和h_j$的相似程度。如果某个时刻$t$,Encoder隐藏层值$h_t$与Decoder之前隐藏层值十分接近,那么该时刻的Encoder隐藏层值应该跟多地输出到序列表示$C$中,这样相当于我们更加注意这个时刻的序列输入,故而得名Attention机制。
参考文献
- Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation, arXiv:1406.1078, Bart van Merri¨enboer Caglar Gulcehre, etc..
- 《深度学习》, 中国工信出版集团, Ian Goodffello, Yoshua Bengio, Aaron Courville
- 知乎《【NLP】Attention原理和源码解析》,李如, https://zhuanlan.zhihu.com/p/43493999